Technical platform specifications basic implementation and generic RDF API
Deliverable 5.1 and 5.3
Document History
| Ver. | Name | Date | Remark |
|---|---|---|---|
| v0.1 | Sergio Fernández | 08.05.2014 | Created initial structure |
| v0.2 | Sergio Fernández, Jakob Frank, Reto Gmür | 05.06.2014 | Added content to some main sections |
| v0.3 | Carl Blakeley, Kingsley Idehen, Rupert Westenthaler, Sergio Fernández | 16.06.2014 | Integrated contributions from other authors |
| v0.5 | Sergio Fernández, Reto Gmür | 25.06.2024 | First internal review version |
| v0.6 | Sebastian Schaffert, Sarven Capadisli | 29.06.201 | First internal review |
| v0.7 | All | 30.6.2014 | Addressed review comments |
| v0.8 | Reto Gmür | 8.9.2014 | Reworked overall structure |
| v1.0 | Reto Gmür | 7.10.2014 | Addressed review comments |
Documentation Information
- Deliverable Nr Title: D5.1 Technical platform specifications and basic implementation
- Lead: Reto Gmür (BUAS)
- Authors: Sergio Fernández, Jakob Frank, Rupert Westenthaler (SRFG), Carl Blakeley, Kingsley Idehen (OGL), Reto Gmür, Adrian Gschwend (BUAS)
- Publication Level: Public
Document Context Information
- Project (Title/Number): Fusepool P3 (609696)
- Work Package / Task: WP5 / T5.1 & T5.2
- Responsible person and project partner: Reto Gmür (BUAS)
Quality Assurance / Review
- Danilo Giacomi
- Giuliano Mega
Official Citation
Fusepool-P3-D5.1
Copyright
This document contains material, which is the copyright of certain Fusepool P3 consortium parties.
This work is licensed under the Creative Commons Attribution 4.0 International License. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
Executive Summary
The goal of Fusepool P3 project is to make publishing and processing of public data as linked data easy. For this purpose Fusepool P3 develops a set of software components that integrate seamlessly by well defined APIs basing on Linked Data Best Practices and the Linked Data Platform standard.
To ensure longevity of the code and the APIs developed within Fusepool the software is designed so that the individual components can be used not only as parts of the overall software, but also individually. The architecture is not tied to a particular runtime environment but bases exclusively on web standards. This allows components to be implemented using any language and framework.
As a consequence of this the focus of the platform is not to build a central application into which the components are added as plugins but mainly specifying generic APIs to allow the interaction of loosly coupled modules. This is the reason why this document covers both D5.1 (Technical platform specifications and basic implementation) as well as D5.3 (Data storage access via generic RDF APIs). The platform is what emerges from components communicating with generic RESTful RDF APIs. This focus on standards and loose coupling will provide the extensibility to cover both the current as well as future end-users needs. This is because new developers as well as new platforms and tools can be integrated very quickly.
The Fusepool P3 process is divided in the following four steps: exploration, extraction, enrichment and delivery. The software provides tools for the last 3 steps:
- Extraction: Data from various sources and formats is transformed to RDF and thus made usable in the Linked Open Data (LOD) Cloud.
- Enrichment: Entity recognition, Natural Language Processing (NLP), Interlinking as well as human processing such as by Crowdsourcing allow to enrich the available data increasing its value to its and to application builders.
- Delivery: The actual delivery of the data can be separated into making it available via Linked Data standards and the actual presentation to the user with apps running on desktops and mobile devices.
This document describes the modular architecture of the Fusepool P3 platform. It describes the modularization, the available and planned implementations of modules and shows how the modules play together to implement the use cases and provide the toolkit envisaged by the DOW.
Specification for APIs as well as the source code of a running basic implementation form an integral part of this deliverable.
Acronyms and Abbreviations
| Acronym | Description |
|---|---|
| ABAC | Attribute Based Access Control |
| ACL | Access Control List |
| API | Application Programming Interface |
| BUAS | Bern University of Applied Sciences |
| ETL | Extract, Transform, Load |
| FP3 | Fusepool P3 |
| HTTP | Hypertext Transfer Protocol |
| HTTPS | Secure Hypertext Transfer Protocol |
| IRI | Internationalized Resource Identifier |
| JDBC | Java Database Connectivity |
| JDK | Java Development Kit |
| LDP | Linked Data Platform |
| LDP-BC | Linked Data Platform Basic Container |
| LDPC | Linked Data Platform Container |
| LDP-DC | Linked Data Platform Direct Container |
| LDP-IC | Linked Data Platform Indirect Container |
| LDP-NR | Linked Data Platform Non-RDF Source |
| LDPR | Linked Data Platform Resource |
| LDP-RS | Linked Data Platform RDF Source |
| ODBC | Open Database Connectivity |
| OGL | OpenLink Software Ltd. |
| PPO | Privacy Preference Ontology |
| RDF | Resource Description Framework |
| RDFS | RDF Schema |
| REST | Representational State Transfer |
| SAIL | Storage And Inference Layer |
| SoC | Separation of Concerns |
| SPARQL | SPARQL Protocol and RDF Query Language |
| SQL | Structured Query Language |
| SRFG | Salzburg Research Forschungsgesellschaft mbH |
| SSL | Secure Sockets Layer |
| TLS | Transport Layer Security |
| URI | Uniform Resource Identifier |
| URL | Uniform Resource Locator |
| VAL | Virtuoso Access Control |
| W3C | World Wide Web Consortium |
| WebDAV | Web Distributed Authoring and Versioning |
| WG | Working Group |
| WP | Work Package |
Normative namespaces
In this document the prefixes used in CURIEs shall refer the following IRI prefixed:
Introduction
This document describes the technical specification for the Fusepool P3 platform. It specifies the Fusepool P3 software by describing the basic architectural design choices and at a different level of precision (depending on the current status of the development of the respective components and work packages) the concrete interaction APIs. It aims to present an application that satisfies the high level requirements of the DoW but also the more concrete use cases developed by WP1. The described architecture is the result of discussion with all technical work packages as it affects all software deliverable of the project and not just WP5.
The main goal of the Fusepool P3 architecture is to provide interaction protocols and pattern so that the components can be used in concert to form the Fusepool P3 Platform. The interaction is based on HTTP. For the APIs introduced in Fusepool P3 we strive to adhere to the REST design principles. Also we adhere to the Linked Data principles BernersLee2006. This document also describes some of the workflows to illustrate how the APIs and architectural patterns are applied to satisfy concrete use case.
Uses cases summary
The Fusepool P3 project partners Provincia Autonoma di Trento and Regione Toscana have been publishing Open Data and develop apps in the domain of tourism for several years. During this time both partners gained valuable experience in data creation, maintenance and publication.
Many of the published Open Data sets are used in Android or iOS apps aimed at tourists and/or inhabitants of the region. Some of them are written by the project partners, other apps by 3rd party developers which integrate parts of the published Open Data into their own apps.
As of today the data is mainly available in particular data formats like CSV, KML, XML and JSON. App developers need to download the raw data and process it using their own ETL (Extract, Transform, Load) processes. With every update of the raw data this process has to be triggered for every single application where it is used. If the format of the raw data changed, the process has to be adjusted and cannot be automated. With every new data source, maintenance complexity of these Open Data sets and its apps increases.
Linked Data can help to solve these problems: Data is made available in a standard format (RDF) which provides among others the following benefits[1]:
- Every piece of information (data) has its own identifier (URI/IRI).
- Those identifiers can be resolved via the web (HTTP),
- which acts as a generalized API for developers.
- Standardized vocabularies describe the meaning of the data,
- and allow to relate information with each other.
The Linked Data technology stack [Bizer2009] provides many ways to interact with data in RDF format [Cyganiak2014]. This greatly reduces the overhead needed to integrate data sets into apps and thus increases the value of Open Data. However, one needs new ETL processes to transform raw data to Linked Data. While it facilitates data usage for app developers, Linked Data requires initially more work by the data owner and publisher.
In the past years many powerful tools got developed or extended to support creation and maintenance of Linked Data. Also new W3C standards and vocabularies are developed for turning legacy data into Linked Data. Many of these tools and standards are developed, extended or implemented by Fusepool P3 project partners. The emerging Linked Data Platform Standard (LDP)[7] provide standardized means for making collections of linked data resources accessible.
What is lacking is an integration framework that combines the data transformation to RDF, possible enhancement steps and the publishing of the Linked Data. Fusepool P3 will provide such an integration framework along with User Interface tools that serve both to model the data publication process as well as to coordinate the human interactions that might be required while the data is processed.
This framework will integrate state-of-the-art tools like OpenRefine, OpenLink Virtuoso, Apache Stanbol, and Pundit. The framework is developed and tested based on the requirements by our project partners Provincia Autonoma di Trento and Regione Toscana. Both partners have started working with the platform in an early stage and feedback gets directly integrated into the agile development process of Fusepool P3.
Methodology
The platform is implemented with an agile framework inspired by Scrum [Schwaber2011]. We follow the philosophy of "release early, release often" [Raymond1999]: every iteration results in potentially shippable increments of functionality. Many of these results are indeed shipped, i.e. releases to open source software repositories and as such made available to the community. At the time of this writing several libraries have already been releases and deployed to the Maven Central Repository, the biggest repository for Java libraries. Other components are available for download on Github.
The agile methodology minimizes the risk associated with software development. Far too often the outdated engineering concept of "always throw the prototype away" [Brooks1995] resulted in software being thrown away twice. We are aware that many decisions may be wrong. Or even if they are right we have produced a bad implementation out of it. But we keep components as loosely coupled as possible and release what we have, hoping it will be of use to our users and the community but always ready to improve the components and evolve the platform as a joint effort of all technical work packages.
Once the first milestone of the project was accomplished, the project already has a working platform, something that is ready to be used for starting to develop and integrate all the other components. In parallel, the platform will be also evaluated by external stakeholders that will provide the necessary feedback to feed the following development iterations. The Scrum methodology [Takeuchi1986] internally used for the project development will try to deliver quickly and respond to all these emerging requirements.
Our methodology is heavily inspired by the twelve-factor app [Wiggings2012] principles. This results in a platform composed of many standalone applications. These applications can be implemented using any language and communicate only via well defined protocols. There are no shared dependencies that might cause the entire system to break on an incompatible change, every module includes all the dependencies it needs to run.
Architecture
The architecture is based on components communicating via HTTP and exposing RESTfull APIs. This allows for components being developed in any language and hosted on any platform. After initial discussions on the architectural principles (see [2] and [3]) the decision was taken to have the components very loosely coupled and interacting only via HTTP, this design choice was made with the following goals:
- Reusability of Fusepool components is maximized
- Distributed development is facilitated
- It is easy for developers to understand and extend the software
- Ensure longevity of the software
- The software is simple to deploy and maintain in organizational IT environments (DoW 1.2.2)
In combination these goals ensure a platform that can satisfy both the current as well as future end user requirements.
Once the decision was taken on how components should interact the question was where the boundaries between components should be defined and how the components build the overall platform. The following figure depicts the high-level architecture for the Fusepool P3 platform:

The diagram shows how the UI and other clients access the fusepool P3 primarily via an LDP transforming Proxy which exposes a front-end conforming to the LDP specification [Speicher2014] with the addition of the Transforming Container API [TODO link]. The proxy transparently handles transformation processes by calling in background the actual transformers, and sending back the data to the platform once the process has finished. The clients can also directly access transformers via their REST API (transformer API) [TODO link] or use a SPARQL 1.1 [SPARQL11] endpoint.
As the name suggests transformer data. The term ans the API are used broadly both for the functionality provided by WP 2 as well as by WP 3. It comprises the transformation from non-RDF content to RDF as well as the transformation from content without annotations to content with annotations.
The components drawn in blue are not actually separable components that interact via HTTP. While an LDP implementation could in principle interact with the RDF Triple Store exclusively via SPARQL and HTTP for performance reasons it is not implemented this way but is rather more tightly coupled to the implementation of the triple store. Similarly some custom services realized in T5.4 will be implemented to directly interact with the triple store; such services are only implemented if the development of the UI shows that an interaction via the standard mechanism SPARQL and LDP is not feasible or not providing an adequate level of performance.
For the implementation of LDP (without the transforming container API) the concrete implementations that the partners bring into the consortium are Apache Marmotta^[4]^ from SRFG and OpenLink Virtuoso^[5]^ from OGL. With the exception of the T5.4 components any generic LDP implementation that supports read/write access can be used. Some more concrete details about the requirements for such implementations will be described below.
All components are going to be described in sufficient detail in the upcoming sections.
To summarize: This architecture does not make the platform the common runtime for all components. On the contrary, by default each component, including all transformers, are individual processes interacting via HTTP as the interaction interface. An exception to this are the backend related components (LDP, SPARQL, RDF Triple Store and the possible custom backend services) which may be more tightly coupled between themselves (i.e., running under the same runtime) due to non-functional requirements.
Components
The Fusepool P3 platform is composed of four core components: clients, the LDP Transforming Proxy, transformers and backends.
Clients
From the point of view of the platform, clients will be all those components of the project interacting with the platform. They mainly will use standard interfaces, such as LDP or SPARQL, that allow the final users[6] to use the platform in a seamless way.
Further details will be described in WP4’s deliverables.
Transformers
Data transformation components are responsible for transforming data from legacy formats (e.g. structured formats like vCard or Facebook OpenGraph, or unstructured formats like plain text) to RDF. The can also transform data without changing it's format such as by adding or refining annotations.
As the term "transform" and the derived terms are used very broadly here; it includes processes such as annotating and RDFizing content. Therefore, from the nature of the transformation tasks, in the current scope we can differentiate at least two families of transformers: RDFizers which transform non-RDF data to RDF and annotators which enrich with RDF annotations data in any format. While RDFizers produce RDF data using the ontologies best suited for the concrete data (e.g. FOAF for data describing persons), annotators will used a common set of ontologies as to describe annotations in a common way.
Transformers are identified by an URI which is the entry point of the RESTfull transformation API. Very often a single HTTP Server will provide many related transformers. For example a server on host translate.example.org might provide an a transformer translating from English to German with URI http://translate.example.org/en/de and another transformer translating from Esperanto to Klingon at URI http://translate.example.org/eo/tlh. Such a software providing many transformers is called transformer factory.
The transformer API supports both synchronous and asynchronous transformers. While a synchronous transformer returns the transformation result right as the response of the transformation request asynchronous transformer will deliver their results at a later time. Asynchronous transformers might for instance require some user interaction in order to deliver their results.
Transformers may invoke other transformers, we provide a transformer factory to create pipeline transformers. A pipeline transformers invokes a list of transformers in sequence passing the output of one transformer as input to the next transformer and at the end retuning the output of the last transformer. For example this allows to chain a transformer translating the content with a transformer that does named entity extraction, which would be useful if no entity labels are available in the original language.
LDP Transforming Proxy
Fusepool P3 defined the Transforming Container API. This API bases on LDP and provides a way to describe containers (LDPCs) that transform data that is added to such a container by passing it to a transformer.
While it is possible for an LDP implementation to implement this API directly it would be hard to convince vendors of LDP implementations to add support for Transforming Containers, especially as long as this API is hardly known and there are few transformers available. As the API won't become more widely known as long as it is isn't supported this is a prototypical catch-22 situation.
To break out of this dilemma we implemented the P3 Transforming Proxy. This is an HTTP Proxy that is used as a reverse proxy in front of an LDP Server and adds the capabilities described by the Transforming Container LDPC to the proxied instance. The proxy intercepts POST requests: if the request is against an LDPC marked as Transforming Container the proxy will not only forward the request to the proxied LDP instance but also send the contents to the transformer associated to the container. Once the result of the transformation is available, such result will also be posted to the LDPC. Of course, the LDPC can be associated to a pipeline transformer if multiple transformers should be executed.
Backends
All data is persisted to the underlying backend server, which provides the support for the generic interfaces (LDP and SPARQL) and where the data will be persisted in a RDF Triple Store. Both Marmotta and Virtuoso will provide a concrete implementations of this generic component.
APIs and specifications
Components communicate via REST [Fielding2002] over HTTP [Fielding1999] between each other. RDF is used as data model and exchange format in most communications (SPARQL is an exception of this rule). All standard serializations may be potentially used, Turtle [Prudhommeaux2014] is supported by all components implemented within the project.
Interaction between the components as well as with external clients is regulated by the following specifications:
- LDP
- SPARQL
- Transformer API
- Transforming Container API
- User Interaction Request API
- Fusepool Annotation Model (FAM)
Some other APIs are yet to be defined.
LDP
Linked Data Platform 1.0 [Speicher2014], commonly abbreviated as LDP, is a W3C technology which proposes to use HTTP for accessing, updating, creating and deleting resources from servers that expose their resources as Linked Data. It provides clarifications and extensions of the rules of Linked Data [BernersLee2006]. LDP uses standard HTTP and RDF techniques for constructing clients and servers that create, read, and write Linked Data Platform Resources (LDPR). The specification defines a special type of Linked Data Platform Resource: a Container (LDPC). Containers are very useful in building application models involving collections of resources, often homogeneous ones. Resources can be added to containers using the standard HTTP POST method.
Besides a general purpose LDP 1.0 implementation compliant with the specification[11], for the concrete needs of the project:
- Implementation must support the creation of (nested) containers by posting them to an existing container.
- In addition to the normative LDP properties, the description of an LDPC shall be allowed to contain arbitrary properties.
- Further more, the underlying LDP implementation has to support to transparently run behind a Proxy, concretely this means the LDP implementation must not assume the requested IRI to reflect the port it is listening to, e.g. the LDP implementation might be listening to port 8080 but answer requests directed to port 80.
LDP Specification: http://www.w3.org/TR/ldp/
SPARQL 1.1
All Data in the RDF Graphs managed by a Fusepool P3 platform backend can be accessed via SPARQL 1.1 [SPARQL11]. SPARQL is the standard query language for RDF triple stores. While the LDP access allows for browsing the data SPARQL allows to run queries of arbitrary complexity against the data.
Sparql Specifications: http://www.w3.org/TR/sparql11-overview/
Transformer API
The transformer API defines a RESTfull and RDF based API for data transforming components. It supports both synchronous and asynchronous execution of the data transformation tasks. While similar APIs are provided by other projects such as by Apache Any23 (Apache Any23 REST Service) or by Apache Stanbol (Apache Stanbol Enhancer RESTful API) none of these APIs offered the required flexibility. We hope that the advantages of the API we propose, like the RDF service description and the possibility of asynchronous execution will convince other communities to adopt it or might contribute to a new and more broadly accepted standard.
The Specification for the Transformer API is an annex to this deliverable and also available in its latest version at: https://github.com/fusepoolP3/overall-architecture/blob/master/transformer-api.md
Transforming Container API
The Transforming Container API is defined as an extension to the LDP specification to allow special containers to execute a Transformer when a member resource is added via a POST request. This allows to automatically Transform documents when they are added to a Linked Data Platform Container (LDPC).
Basically the process is such: if the representation contains a triple with the LDPC as subject and eldp:transformer as predicate, an implementation invokes the trans:Transformer identified by the object of this triple whenever a LDP-NR is created following a POST request to the Transformer LDPC. The results of the transformation will be added to the same container.
The Specification for the Transforming Container API is an annex to this deliverable and also available in its latest version at: https://github.com/fusepoolP3/overall-architecture/blob/master/transforming-container-api.md
User Interaction Request API
Some components such as transformers may require some user interaction at some points of processing. While components are free to get a users attention in any way (such as by sending emails) the user interaction request API allows to request for user attentions in a unified way allowing all requests for interaction showing up in a cockpit UI-Application.
The User Interaction Request API describes how an LDPC is used to maintain a registry of requests for interaction. Components submit a URI to this registry and remove the URI once the interaction completed. The UI component provides the user a link to the submitted URI. The component is free to present any web-application at that URI suitable to perform the required interaction.
The Specification for the User Interaction Request API is an annex to this deliverable and also available in its latest version at: https://github.com/fusepoolP3/overall-architecture/blob/master/user-interation-request-api.md
Fusepool Annotation Model (FAM)
In Fusepool P3 annotators are expected to produce annotation from textual content, either unstructured or extracted from any other structured format. All annotators produce RDF using a common annotation model as described by this section. This is important to pipe annotators, allowing configurations using multiple annotation services.
The base structure of this Annotation Model will be fully compatible with Open Annotation [Sanderson2013], but defining some additional relations to ease the consumption - especially the retrieval of Selectors for Annotations. The following figure provides an overview on the chosen model.
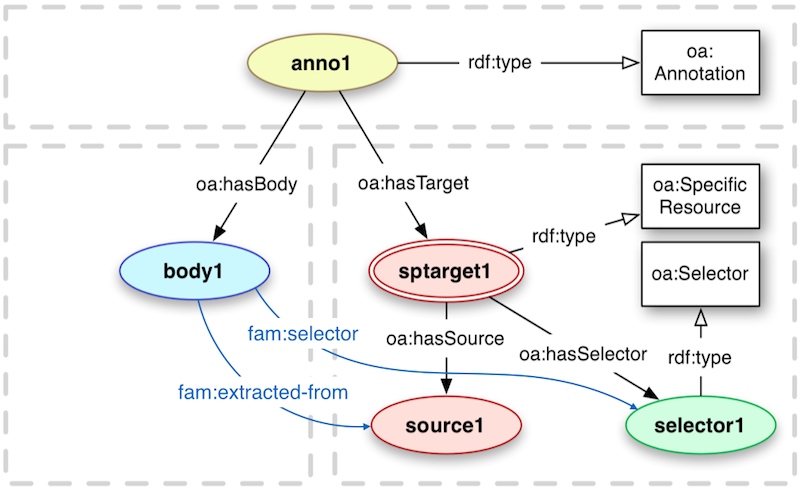
Annotations describe (annotate) associations between related resources. An annotation based on the Fusepool P3 Annotation Model will consist of the following parts:
- oa:Annotation providing metadata and provenance information about the produced annotations
- oa:SpecialResource representing the n-ary relation between the oa:Annotation, oa:Selector and the source.
- the source represented by the IRI of the annotated text
- an annotation body that formally describes the annotation
A fam:selector property is introduced to provide a shortcut between the annotation body and the 0..* selectors. The fam:extracted-from property provides a direct link between the annotation body and the source. Those two properties allow a annotation body centric consumption of annotator results. Then clients, instead of manually joining over the intermediate resources (?annotation and ?sptarget) with a SPARQL query like:
PREFIX oa: \<http://www.w3.org/ns/oa\#\>
SELECT ?body ?source ?selector
WHERE {
?annotation a oa:Annotation ;
oa:hasBody ?body ;
oa:hasTarget ?sptarget .
?body a fam:TextAnnotation ;
oa:hasBody ?body .
?sptarget oa:SpecificResource ;
oa:hasSource ?source ;
oa:hasSelector ?selector .
}
Instead they can directly retrieve the required information with a much simpler and faster query:
PREFIX oa: \<http://www.w3.org/ns/oa\#\>
PREFIX fam: \<http://vocab.fusepool.info/fam\#\>
SELECT ?body ?source ?selector
WHERE {
?body a fam:TextAnnotation ;
fam:extracted-from ?source ;
fam:selector ?selector .
}
In addition to this core structure model the Fusepool Annotation model also defines a set of Annotation Types for the annotation of different analysis results:
- Language Annotation: used to describe the Language of the analyzed text
- Text Annotation: used to describe Named Entities detected in the text. Such entities can originate from Named Entity Recognition (NER) tools annotators that detect mentions of Entities based on Dictionaries
- Entity Annotation: used to suggest Entities part of some kind of controlled vocabulary for mentions in the text. Entity Annotations are suggestions for Text Annotations. The oa:Choice construct is used for modeling those
- Topic Annotation: used to classify a document along topics defined in some classification scheme (e.g. skos:Concepts part of a skos:ConceptScheme)
All those Annotation Types will act as annotation bodies as defined in the core annotation structure. Transformers that require annotations not covered by the predefined Annotation Types can define their own types (within their own namespace). Those transformer specific Annotation Types can be used similar to the predefined one. It is also possible to extend existing Annotation Types (e.g. by defining additional properties). NOTE that components consuming FAM annotations might not support custom annotation types.
This section defines the first version of the Fusepool P3 Annotation Model[19]. The final specification of the FAM will be presented as part of Deliverable D3.1 (M12).
More specification
Following an agile development approach specification of the application is an ongoing process. Currently some more specification are foreseen:
- Transformer Registry
- Transformer Factory Registry
The Transformer Factory Registry allows the UI to point the user to a web application allowing the creation of Transformers, such an application might require to choose a taxonomy in the case of an entity recognizing annotator. In the case of the application to create a pipeline transformer the user will have to choose transformers and put them in the right order, this application will use the Transformer Registry to show the available transformers.
These registries will be modeled in a similar way as the User Interaction Request API described above. So rather than introducing new components the regular LDP capabilities are used to maintain these registries.
Access control
Access Control is a mechanism through which an agent (in this case the platform) permits to perform certain operations on resources as specified by concrete policies. Within this document, the resources are RDF resources, exposed either by LDP or SPARQL, and the access control will not operate at a different granularity (graphs or triples). When access control come into play, the platform must restrict some operations on some resources. These operations are the typically described by the RESTful principles.
Access control is a recognized open issue when interacting with RDF / Linked Data using HTTP methods [Costabello2013], and LDP 1.0 is not yet seriously addressing such issue[20]. Therefore please notice that the platform will not go beyond the state of the art on this aspect; i.e., we are not going to provide a new access control proposal. But the Fusepool P3 platform is just going to implement the best possible solution for the goals of the project among the different alternatives already available out there.
Given the proposed architecture, where all the interaction to the platform is done via the LDP Transformation Proxy Layer (further details can be found at Sections 2.1 and 3.1), access control not relying on HTTP Headers (e.g. WebID) must be at least partially be handled by a proxy handling the requests as they come in^[e]^. This means that a HTTPS proxy might handle the request before the requests are processed by the LDP Transformation Proxy described above. This HTTPS Proxy can of course rely on information stored in the proxied LDP implementation describing the users and their rights. Following the design principle of Separation of Concerns (SoC) the LDP Transformation Proxy only implements HTTP, no TLS/SSL support over HTTPS. Therefore such circumstance needs to be properly handled when designing the access control mechanisms. For all these reasons, access controls is not yet part of the basic implementation delivered together with this report. There are still many issues to clarify before we would be able to provide a specification that could fit in the overall architecture.
As a reference in the following sections we describe the access control mechanisms of the particular Linked Data Platform (Apache Marmotta or OpenLink Virtuoso) providing the base layers of the FP3 framework (the blue components in the architecture diagram on Section 2).
Marmotta access control
Apache Marmotta implements some basic mechanisms for access control. By default HTTP Basic authentication [Fielding1999] is used for authentication and authorization [21], both for all web services (SPARQL, LDP, etc) and the administration user interface. The configuration is based on ACL rules, using users and roles, grouped in profiles for simplifying permission management.
In addition, Marmotta also has experimental support for fine-grained access-control within the RDF triples [22] by providing access control over a Sesame SAIL using PPO [Sacco2011]. Although in principle such granularity level of access control would not be required by the project, as discussed above. The roadmap of the project also includes other authentication technologies, such as WebID [23] or OAuth [24], which also could be addressed with the implementation of the Fusepool P3 platform. In the end the evolution of the requirements, both internal in the project and external [25], should guide that process.
Virtuoso access control
Virtuoso provides numerous options for access control - some specific to a particular realm. For instance:
- Protected SPARQL endpoints associated with specific authentication methods, e.g. /sparql-auth, /sparql-oauth, /sparql-webid [Fielding1999, Hardt2012, Story2009, Recordon2006].
- SPARQL roles restrict the types of SPARQL commands a database user may perform.
- Graph level security allows the setting of permissions bit masks to set the read/write (and sponge) permissions on specific RDF graphs to control public access or specific users.
However, OpenLink’s preferred generic access control mechanism for Virtuoso is VAL, its Virtualized Authentication Layer^[26]^. VAL provides a virtualized layer that loosely couples: Identifiers (WebIDs that denote Agents), Identification (WebID-Profile documents that describe Agents), Authentication (WebID-TLS and other protocols for Identification claims verification), and Authorization (via the use of ACLs or Data Access policies represented in RDF). VAL enables protection of any HTTP and SQL (via ODBC or JDBC connections) accessible resource(s). Thus, it provides the basis for controlling access to LDP resources exposed by the Virtuoso LDP, for protecting Virtuoso SPARQL endpoints or specific RDF store named graphs, or WebDAV resources etc.
VAL vs LDP WG Requirements for Access Control
VAL offers a superset of the LDP access control requirements outlined by the Linked Data Platform Working Group [27]. It broadly supports the following W3C requirements:
- Access Control Graphs - which describe which agents have access to which resources and the modes of access allowed.
- Access control on HTTP manipulation of resources.
- Editability of access control rules using HTTP.
- Agents can authenticate themselves to the server with an identifier or as the owner of a token.
- Ability to specify access privileges at a fine-grained level.
- Ability to specify a collection of agents or resources, identified by IRIs or IRI patterns.
Virtuoso Authentication Layer (VAL)
VAL provides both authentication and access control services through an internal Virtuoso API or by two public HTTP APIs, a ‘standard’ HTTP API and a RESTful variant, which manage rules and groups via their URLs. Both are Turtle-based. All the VAL authentication mechanisms are supported.
Users attempting to access a VAL-protected resource must first login and authenticate themselves through a VAL-supplied authentication dialog. After establishing a VAL session, their access permissions on the resource are checked. Virtuoso LDP resources and containers could be protected in this way, once the required VAL hooks are in place.
The supported authentication methods are:
- HTTP authentication (for Virtuoso SQL and WebDAV user accounts)
- Basic PKI, BrowserID, OpenID, WebID-TLS
Third party OAuth services:
Numerous services including Facebook, Twitter, LinkedIn and Google.
- Note: Not all OAuth services require a Virtuoso SSL endpoint. Such services would remove the need for the LDP Transformation Proxy to support HTTPS.
VAL’s generic ACL layer is based in its entirety on RDF statements and entity relations logic, so rules, groups, authorization grants etc., are all in the form of RDF statements persisted to private graphs in the RDF store. Authorization rules are described using terms from the W3C ACL ontology [28] and the OpenLink ACL ontology [29]. This system also supports restrictions which restrict arbitrary values based on the authenticated user. These can be used to limit the number of query results, enforce quotas etc.
VAL ACL Rule System Overview
The ACL rule system allows any authenticated person (including any 3rd-party service IDs which have no corresponding Virtuoso SQL account) to create ACL rules for any resource they own or they have grant rights for. A resource is any entity identified by a IRI. This could be an LDPR or LDPC, or an transformer. VAL manages and reports the permissions on the resource, but the logic supporting the resource access is responsible for enforcing those permissions.
Rules and groups are stored in private named graphs within the triple store, as are resource ownership details. The rules grant read, write or sponge permission on a resource, or the ability to grant these permissions. Custom permissions can also be defined.
Below is a basic example of an ACL rule granting read access to a
user authenticating through their Facebook login,
http://www.facebook.com/jsmith, to
resource http://demo.fusepoolp3.eu/assets:
@prefix oplacl: \<http://www.openlinksw.com/ontology/acl\#\> .
@prefix acl: \<http://www.w3.org/ns/auth/acl\#\> .
\<\#rule\> a acl:Authorization ;
oplacl:hasAccessMode oplacl:Read ;
acl:agent \<http://www.facebook.com/jsmith\> ;
acl:accessTo \<http://demo.fusepoolp3.eu/assets\> ;
oplacl:hasScope \<urn:myscope\> .
In addition to individual person ACLs granting access to an individual, rules can grant access to a simple group, a conditional group, or everyone, i.e. make a resource public. Rather than consisting of a list of members, conditional groups define a set of conditions. These conditions typically test attributes of the X.509 client certificate provided by the authenticated user’s WebID, but can also be conditions evaluated as part of a SPARQL ASK query. Every authenticated person matching these conditions is seen as part of the group. VAL’s Conditional Groups feature provides the basis for Attribute Based Access Control (ABAC [30]).
Workflows
This section shall illustrate concrete interaction with the P3 software.
Registration of a transformer
The exact vocabularies and usage have not yet been specified, the following should just give an idea in which direction development is going.
The registration of transformers is done by using a regular LDP Interaction Model. The Fusepool P3 platform will register a LDP Container for known transformers. This registry is used by the client when creating transformation containers as well as when creating pipeline transformers.
The following HTTP traces outline some more details about this process. The necessary request to register a new transformer in the platform, using the HTTP Slug header [RFC5023] according LDP to request "example" as unique identifier, would be something like:
POST /registry
Host: demo.fusepoolp3.eu
Slug: example
Content-Type: text/turtle
@prefix dct: <http://purl.org/dc/terms/> .
@prefix fp3: <http://vocab.fusepool.info/fp3#> .
<> a fp3:RegistryEntry;
fp3:entry <http://example.org/vcard-transformer>.
<http://example.org/vcard-transformer> a fp3:TransformationService ;
dct:title "An example vCard transformer"@en.
the included transformer description HTTP request message body, using the RDF serialization specified by the Content-Type header. Then, the response would look like:
HTTP/1.1 201 Created
Server: FusepoolP3/0.1.0 (build 2+)
Last-Modified: Mon, 16 Jun 2014 08:54:14 GMT
ETag: W/"1402908854000"
Location: http://demo.fusepoolp3.eu/registry/example
Content-Length: 0
Date: Mon, 16 Jun 2014 08:54:14 GMT
Then, a request to the new entry:
GET /registry/example
Host: demo.fusepoolp3.eu
Accept: text/turtle, application/rdf+xml;q=.8, \*/\*;q=.1
will return something like:
HTTP/1.1 200 OK
Date: Mon, 16 Jun 2014 08:57:32 GMT
Connection: close
Content-Type: text/turtle
@prefix dct: \<http://purl.org/dc/terms/\> .
@prefix fp3: \<http://vocab.fusepool.info/fp3\#\> .
\<http://demo.fusepoolp3.eu/registry/example\> a fp3:RegistryEntry ;
fp3:entry \<http://example.org/vcard-transformer\> .
\<http://example.org/vcard-transformer\> a fp3:TransformationService ;
dct:title "An example vCard transformer"@en .
Registering a transformer factory
Similar to the above but what is registered are the IRI of transformer factory. This IRI, http://service.example.org/openrefine in the example from Section 2.1.2, dereferences to a representation suitable to be used by a human to create a transformer, ideally a HTML document.
A transformer is identified by a IRI. While it is possible that a transformer is an individual implementation, it is also common that the implementation is rather a transformer factory, that is a service that requires additional configuration for actually providing a transformer. This additional configuration is typically encoded in the IRI of the resulting transformers. For example a transformer for the OpenRefine rule file located at http://example.org/rules might have the IRI http://service.example.org/openrefine?rules=http://example.org/rules the transformer factory could have the IRI: http://service.example.org/openrefine, it is important to note that the latter IRI does not identify a transformer. Transformers provided by the same transformer factory will typically share the same runtime. Note that the choice of runtime is up to the implementation. In this architecture there are no requirement on the runtime environment, as long as it implemented the Transformation REST API.
Creating a Transforming Container
LDP does not specify how containers are created. Whatever method the underlying LDP implementation supports to create container can also be used to create tranforming container as long as it allows to add an fp3:transformer property linking the transformer from the created container. A Fusepool P3 compliant LDP implementation must support the creation of containers by posting them to the transformers root container.
POST /ldp
Host: demo.fusepoolp3.eu
Slug: transforming-container
Content-Type: text/turtle
@prefix dct: \<http://purl.org/dc/terms/\> .
@prefix fp3: \<http://vocab.fusepool.info/fp3\#\> .
@prefix eldp: \<http://vocab.fusepool.info/eldp\#\> .
\<.\> a eldp:TransformationContainer , ldp:DirectContainer ;
:transformer \<http://example.org/vcard-transformer\> .
The server response MUST have status code 201 and MUST contain a location header specifying the IRI of the created resource
HTTP/1.1 201 Created
Server: FusepoolP3/0.1.0-SNAPSHOT (build 2+)
Last-Modified: Mon, 16 Jun 2014 08:54:14 GMT
ETag: W/"14028798789"
Location: http://demo.fusepoolp3.eu/ldp/transforming-container
Link: \<http://p3.fusepool.eu/transformation\>; rel="describedby"
Link: \<http://www.w3.org/ns/ldp\#Container\>; rel="type"
Link: \<http://vocab.fusepool.info/eldp\#TransformationContainer\>;
rel="type"
Content-Length: 0
Date: Mon, 16 Jun 2014 08:54:14 GMT
In the above example the response contains some additional information:
- The Link header with rel="describedby" may indicate some implementation restrictions, in this case all details around the LDP Transformation Proxy that will be described with more detail in following sections of this document.
- The Link headers with rel="type" indicates the type of the created resource in the LDP hierarchy, where the Fusepool P3 workflow adds a non-normative type denoting the extended interaction model.
A GET request to the newly created container at http://demo.fusepoolp3.eu/ldp/transforming-container could look like this:
GET /ldp/transforming-container HTTP/1.1
Host: demo.fusepoolp3.eu
Accept: text/turtle; charset=UTF-8
Prefer: return=representation; include="http://www.w3.org/ns/ldp#PreferEmptyContainer"
Response:
HTTP/1.1 200 OK
Content-Type: text/turtle; charset=UTF-8
ETag: "\_87e52ce2917987"
Content-Length: 477
Link: \<http://www.w3.org/ns/ldp\#Container\>; rel="type"
Preference-Applied: return=representation
@prefix dcterms: \<http://purl.org/dc/terms/\> .
@prefix ldp: \<http://www.w3.org/ns/ldp\#\> .
@prefix fp3: \<http://vocab.fusepool.info/fp3\#\> .
@prefix eldp: \<http://vocab.fusepool.info/eldp\#\> .
<http://demo.fusepoolp3.eu/ldp/transformation/example>
a eldp:TransformationContainer, ldp:DirectContainer ;
dcterms:title "An transformation LDP Container for vCard" ;
ldp:membershipResource
<http://demo.fusepoolp3.eu/ldp/transformation/example> ;
ldp:hasMemberRelation ldp:member ;
ldp:insertedContentRelation ldp:MemberSubject ;
dp:transformer \<http://example.org/vcard-transformer\> .
With a supported RDF format in the Accept header the request MUST yield to a response entity serializing a graph with at least the triple with the fp3:transformer predicate.
Adding content to a Transformer Container
Data is ingested in the platform also using regular LDP interaction. The proxy transparently handles the transformation process, normally when posting LDP-NRs (Linked Data Platform Non-RDF Source resources) to the special transformation containers. The following sequence diagram depicts the high-level interaction for a transforming container using a synchronous transformers:

Coming down into more detail, in the case of a synchronous transformation, the client HTTP interaction is rather simple. The client posts data to the LDPC:
POST /ldp/transformation/example
Host: demo.fusepoolp3.eu
Accept: text/turtle, application/rdf+xml;q=.8, \*/\*;q=.1
Content-Type: text/vcard
Slug: corks
Content-Length: 164
BEGIN:VCARD
VERSION:4.0
FN:Corky Crystal
NICKNAME:Corks
TEL;TYPE=home,voice;VALUE=uri:tel:+61755555555
EMAIL:[email protected]
REV:20080424T195243Z
END:VCARD
And it gets back the the IRI of the newly created resource
HTTP/1.1 201 OK
Date: Mon, 16 Jun 2014 09:01:52 GMT
Connection: close
Location: http://demo.fusepoolp3.eu/ldp/transformation/example/corks
The newly created resource will immediately be a member of the container. The results of the transformer will be available as a member of the container after the transformer terminates the transformation. Internally the proxy handles the invocation to the endpoint provided by the concrete transformer, and the storage of the data.
So when a GET request is sent after the transformation process is completed the interaction might look as follows:
GET /ldp/transformation/example HTTP/1.1
Host: demo.fusepoolp3.eu
Accept: text/turtle; charset=UTF-8
And the response SHOULD look like:
HTTP/1.1 200 OK
Content-Type: text/turtle; charset=UTF-8
ETag: "\_87e52ce2917987"
Content-Length: 477
Link: \<http://www.w3.org/ns/ldp\#Container\>; rel="type"
@prefix dcterms: \<http://purl.org/dc/terms/\> .
@prefix ldp: \<http://www.w3.org/ns/ldp\#\> .
@prefix fp3: \<http://vocab.fusepool.info/fp3\#\> .
@prefix eldp: \<http://vocab.fusepool.info/eldp\#\> .
\<http://demo.fusepoolp3.eu/ldp/transformers/example\>
a eldp:TransformationContainer , ldp:DirectContainer;
dcterms:title "An transformation LDP Container supporting vCard" ;
ldp:membershipResource
\<http://demo.fusepoolp3.eu/ldp/transformers/example\>;
ldp:hasMemberRelation ldp:member ;
ldp:insertedContentRelation ldp:MemberSubject ;
fp3:transformer \<http://example.org/vcard-transformer\> ;
ldp:member
\<http://demo.fusepoolp3.eu/ldp/transformers/example/corks\> .
Basic Implementation
All the code developed within Fusepool P3 is available on GitHub [31]. Currently we provide some first implementation of all components except he UI. Also we provide libraries to easily develop Transformers in Java, usage of this library is documented in a How-To 39. To make development of clients easier we also provide a client-library, the library abstracts away the differences of the synchronous and the asynchronous interaction protocol.
We provide an LDP server based on Apache Marmotta that has been tested to work together with the LDP Proxy we provide.
Apart from the Pipeline Transformer mentioned above we have implemented several transformers such as for:
- OpenRefine
- Silk
- Regex (as an example in How-To)
- Entity recognition based on SKOS Taxonomies
Also several Virtuoso Sponger Cartridges as well as several Virtuoso enhancers are available as Transformers.
Deployment architecture
All component can run on any platform that can expose HTTP services. The components of the reference implementation may require some common runtimes readily available on common platforms.
A et of basic bash scripts is provided to startup all components on Unix-based environments.
Conclusions and future work
This deliverable provides the initial architectural specification and basic implementation of the Fusepool P3 platform. The focus was set on clean interaction pattern to allow productive development in a team using disparate technologies and to allow deployment in various infrastructural settings and for different needs. We are aware that several questions still need to be defined. For example, this first version triggers the discussion of some core aspects, such as access control. Also the debuggability and logging of the process may need to be standardized to accommodate future use cases, this may include data staging on each transformation performed, rollback and provenance. We are confident that the basic architecture as well as our methodology provides a robust framework to address these issues.
The main goal of this document is to set the basic pillars where the complete Fusepool P3 project can be built on top of. This document accommodates the idea outlined in the proposal to the current status of the technology. Together with this document an open source implementation has been delivered, including the basic implementation of some of the core components described above. All these components have to evolve together the rest of the project, and moved towards the high-level goal of providing an integrated data-value chain management platform.
References
| Ref. | Description | |
|---|---|---|
| BernersLee2006 | Berners-Lee, T. (2006). Design issues: Linked Data. W3C. | |
| Bizer2009 | Bizer, C., Heath, T., & Berners-Lee,T. (2009). Linked data-the story so far. International journal on semantic web and information systems, 5(3), 1-22. | |
| Brooks1995 | Brooks Jr, F. P. (1995). The Mythical Man-Month: Essays on Software Engineering, Anniversary Edition (2nd Edition) | |
| Costabello2013 | Costabello, L., Villata, S., Rocha, O. R., & Gandon, F. (2013). Access Control for HTTP Operations on Linked Data. The Semantic Web: Semantics and Big Data, 185-199. | |
| Cyganiak2014 | Cyganiak, R., Wood, D., & Lanthaler,M. (2014). RDF 1.1 concepts and abstract syntax. Recommendation, W3C. | |
| Fielding1999 | Fielding, R., Gettys, J., Mogul, J.,Frystyk, H., Masinter, L., Leach, P., et al. (1999). Hypertext transfer protocol–HTTP/1.1. RFC 2616, June. | |
| Fielding2002 | Fielding, R. T., & Taylor, R. N. (2002). Principled design of the modern Web architecture. ACM Transactions on Internet Technology (TOIT), 2(2), 115-150. | |
| Fowler2006 | Fowler, M., & Foemmel, M. (2006). Continuous integration. Thought-Works. http://www.thoughtworks.com/Continuous Integration.pdf. | |
| Hardt2012 | Hardt, D. (2012). The OAuth 2.0 authorization framework. | |
| Prudhommeaux2014 | Prud’hommeaux, E., Carothers, G., Beckett, D., & Berners-Lee, T. (2014). Turtle–Terse RDF Triple Language. Recommendation, W3C. | |
| Raymond1999 | Raymond, E. (1999). The cathedral and the bazaar. Knowledge, Technology & Policy, 12(3), 23-49. | |
| Recordon2006 | Recordon, D., & Reed, D. (2006). OpenID 2.0: a platform for user-centric identity management. Proceedings of the second ACM workshop on Digital identity management. ACM. | |
| RFC2119 | Bradner, S. (1997). RFC 2119: Key Words for use in RFCs to Indicate Requirement Levels. 1-3. | |
| RFC2616 | Fielding, R., Gettys, J., Mogul, J.,Frystyk, H., Masinter, L., Leach, P., et al. (2006). RFC2616: Hypertext transfer protocol–HTTP/1.1, 1999. | |
| RFC5023 | Gregorio, J., & de Hora, B. (2007). RFC 5023: The Atom Publishing Protocol. Internet Engineering Task Force (IETF) Request for Comments. | |
| RFC7231 | Fielding, R., & Reschke, J. (2014). RFC7231: Hypertext Transfer Protocol(HTTP/1.1): Semantics and Content. | |
| RFC7240 | Snell, J. (2014). RFC7240: Prefer Header for HTTP. | |
| Sacco2011 | Sacco, O., & Passant, A. (2011). A Privacy Preference Ontology (PPO) for Linked Data. LDOW 2011. | |
| Sanderson2013 | Sanderson, R., Ciccarese, P., Van deSompel, H. (2013). Open Annotation Data Model. Community Draft, W3C. http://www.openannotation.org/spec/core/ | |
| SPARQL11 | The W3C SPARQL Working Group (2013).SPARQL 1.1 Overview. Recommendation,W3C. http://www.w3.org/TR/sparql11-overview/ | |
| Schwaber2011 | Schwaber, K, Sutherland, J (2011). The Scrum Guide | |
| Speicher2014 | Speicher, S., Arwe, J., Malhotra, A.(2014). Linked Data Platform 1.0. Candidate Recommendation, W3C. http://www.w3.org/TR/ldp/ | |
| Story2009 | Story, H., Harbulot, B., Jacobi, I.,& Jones, M. (2009). FOAF+SSL: Restful authentication for the social web. Proceedings of the FirstWorkshop on Trust and Privacy on theSocial and Semantic Web (SPOT2009). | |
| Takeuchi1986 | Takeuchi, H., & Nonaka, I. (1986). The new new product development game. Harvard business review, 64(1), 137-146. | |
| Wiggings2012 | Wiggins, A. (2012). The twelve-factor app. http://12factor.net/ |
Copyright Fusepool P3 Consortium /
[2] https://github.com/fusepoolP3/overall-architecture/blob/master/architectural-principles.md
[3] https://github.com/fusepoolP3/overall-architecture/blob/20dc491a3f9ced38061fb853d8cf0789b634b755/platform-architectural-proposal-srfg.md
[4] http://marmotta.apache.org
[5] http://virtuoso.openlinksw.com
[6] For the scope of this document, the "final user" is a data manager who will interact with the tools produced by the project.
[8] http://wiki.opensemanticframework.org/index.php/RDFizer_Concept
[10] http://stanbol.apache.org
[11] According the official W3C LDP Test Suite, available at http://w3c.github.io/ldp-testsuite
[12] http://openrdf.callimachus.net/sesame/2.7/docs/system.docbook?view#The_SAIL_API
[13] http://github.com/fusepoolP3/marmotta-virtuoso
[14] http://s.apache.org/gsoc-2014-marmotta-ldp-over-sparql
[15] https://github.com/fusepoolP3/overall-architecture/blob/2c0f3a7bdcc7174768b87f300bbd6c16a106355f/data-transformer-api.md
[16] https://github.com/fusepoolP3/overall-architecture/blob/master/data-transformer-api.md
[17] https://github.com/fusepoolP3/overall-architecture/blob/5eff446953449ec408a5c3ce87ae1f345e4f4ee2/transforming-container-api.md
[18] https://github.com/fusepoolP3/overall-architecture/blob/master/transforming-container-api.md
[19] https://github.com/fusepoolP3/overall-architecture/blob/69ae9f866302cfa00ede64de77bba36a88bbbb12/wp3/fp-anno-model/fp-anno-model.md
[20] https://www.w3.org/2012/ldp/wiki/AccessControl
[21] http://marmotta.apache.org/platform/security-module.html
[22] http://bitbucket.org/srfgkmt/s-watchdog
[23] http://issues.apache.org/jira/browse/MARMOTTA-222
[24] http://issues.apache.org/jira/browse/MARMOTTA-432
[25] http://www.w3.org/2012/ldp/wiki/AccessControl
[26] Please, note that VAL is a component of Virtuoso Commercial Edition only, and it is not part of Virtuoso Open Source Edition. If required, OpenLink would allow the Fusepool P3 consortium to use Virtuoso commercial edition with a time limited license for the duration of the project; regular licensing will apply when the project is completed. \ Anyway, this architecture has been designed to allow such commercial extensions without affecting the overall pipeline. Therefore this commercial component is just an optional extension, which is not required to run the open source version of the Fusepool P3 platform.
[27] https://www.w3.org/2012/ldp/wiki/AccessControl
[28] http://www.w3.org/ns/auth/acl#
[29] http://www.openlinksw.com/ontology/acl#
[30] http://csrc.nist.gov/projects/abac/
[31] https://github.com/fusepoolP3
[32] https://github.com/fusepoolP3/platform/releases/tag/0.1.0
[33] http://www.apache.org/licenses/LICENSE-2.0
[35] http://stanbol.apache.org
[36] https://www.gnu.org/software/bash/
[37] https://travis-ci.org/fusepoolP3/platform
[38] https://github.com/fusepoolP3/platform
[39] https://github.com/fusepoolP3/p3-transformer-howto/blob/master/transformer-howto.md